
In this post, I will share with you the story of how I combined my love for local music with my passion for data analytics to create Stereo Cincinnati, a data-driven local music blog and playlisting algorithm that showcases the best up-and-coming bands in Cincinnati. By leveraging the power of the Spotify API, I was able to pull back popularity metrics on all the bands in Cincinnati and create “Billboard 100” style playlists organized by genre. I will also discuss the methodology I used to create these playlists and the challenges I faced along the way.
The Origin
At the beginning of 2021, I was also looking for a new hobby. Bread making didn’t appeal to me (I have a gluten allergy), I was never a great crafter (hard to separate my drawings from a 4th grader’s), and I could not find myself getting into the at-home exercise workout videos. So, I stuck with my guns – music and data analytics.
My involvement in the local Cincinnati music scene dates back to 2015. I first started with my Pop/Indie Rock band “Magic Noodle House” playing electric guitar, then moved to my current band “Resonator” playing bass guitar. Over the years, I’ve seen many great bands come and go. But, I’ve also missed a lot of great bands. I’ve always found it frustrating when I didn’t know about a great band until years later. Before 2021, I often scanned local resources for the list of “best bands” but they all typically skewed towards bands that had already made it to some stage or level, or they had missed a band or two that I really wished I would’ve caught. Now, this is not a criticism of the local blogs – we have so many great bands in the area – it’s more of a testament to the amount of talent we have in the area, and how difficult it is to sort through it all. But in 2021, I thought of a solution.

The Solution
I created Stereo Cincinnati, a data-driven local music blog and playlisting algorithm. Using the Spotify API and a source-of-truth list of all Cincinnati bands I created, I was able to pull back popularity metrics on all the bands in Cincinnati and their top songs. This allowed me to create “Billboard 100” style playlists organized by genre, where you could see the top local tracks by artists. You can find these playlists on Spotify here.
I took these playlists to the web via a local blog where I had two posts titled “Cincinnati Music Superlatives”, where I found some “fun data points” about certain artists (e.g. most danceable track, according to Spotify metrics) and “Top Releases of 2021” where I highlighted some of the top new tracks according to the Spotify data and also some of my favorites as well.
But, the true gold nugget of this all is the playlists. This is where the blood, sweat, and tears (well, maybe not blood) actually happened. Let me take you through the creation of the playlists below.
The Methodology
- Find the Artists
- Assemble a list of local music blogs and resources
- CincyMusic was my go-to, highly recommend keeping up to date with the local music scene through them!
- Also scanned through other public Spotify playlists with titles similar to “Cincinnati Local Music / Favorite Cincy Artists / etc.” to help fill in the gaps. This can be risky though, as sometimes the public playlists would have random non-Cincinnati acts mixed in
- Set up a Selenium Python scraping script for the blogs
- This was my first time web scraping, so that was a learning process. I found Selenium to be a great tool but have seen some easier-to-use tools come out more recently, including Webscraper.io a Google Chrome Extension which we actively use at my workplace.
- Determine the necessary information needed in the scrape, and the nice-to-have information (e.g. a direct Spotify link, Artist Genre)
- Scrape and aggregate data, then combine with source data from public Spotify playlists as well
- The final result can be seen here: Stereo Cincinnati Official List of Cincinnati Bands
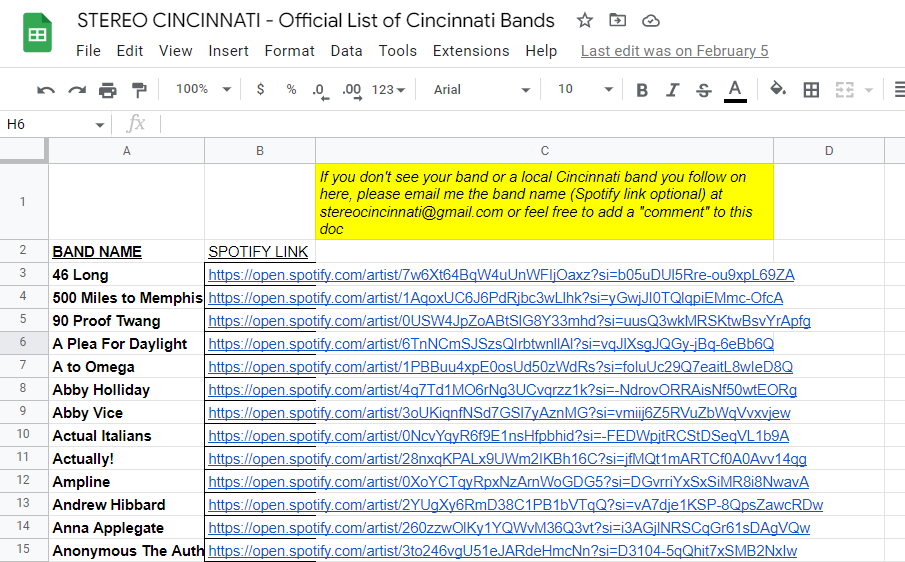
2. Gather the Data
- Get access to Spotify API data via Spotify for Developers and the Spotipy Python package
- Using Spotify Artist Hyperlinks, pull back the top 3 songs by artist
- Had to make the methodology decision around how many tracks per artist. If there was no limit, a few artists would dominate most of the playlists (similar to the Billboard Top 100 when Taylor Swift releases an album).
- Very early on, I had tried using Artist Name as I had full coverage for this column. This went about as well as you would expect, you’d be surprised how many artists share the same name ..
- Assign all the available tracks to a “Cincinnati Total” Spotify playlist. You can see some of this code to do so below, this was the most time-demanding part of the script.
- Looking back on this code 1-2 years later, I’m sure it could’ve been written more efficiently. At the end of the day, it did what it needed to do which was to avoid hitting the API too frequently, give me status updates if any pulls went wrong, and bring back the API metrics I was looking for.
results = []
sp.user_playlist_replace_tracks(username, playlist_id, results)
if token:
sp = spotipy.Spotify(auth=token)
sp.trace = False
for i in range(0,len(input_bands)):
tracks = sp.artist_top_tracks(str(input_bands[i]))
time.sleep(1)
for track in tracks['tracks']:
try:
results_each = []
results_each.append(track['id'])
results.extend(results_each)
time.sleep(0.5)
sp.user_playlist_add_tracks(username, playlist_id, results_each)
print('~')
except:
print('error_with_artist')
else:
token = util.prompt_for_user_token(username=USERNAME, scope = 'playlist-modify user-read-private' , client_id=SPOTIPY_CLIENT_ID, client_secret=SPOTIPY_CLIENT_SECRET, redirect_uri=SPOTIPY_REDIRECT_URI)
print("Playlist Complete!")- Now all of the track data has been collected, group the artists by genre, joining in my separately created Artist//Genre lookup file which was done with a mix of text-matching and human input (it’s helpful to know a lot of the local bands in the area!)
- Pull back the Top 50 songs grouped by genre and sorted by Popularity Score from the “Cincinnati Total” Spotify playlist
- Sort by Popularity and create each genre-specific Playlist (e.g. Top 50 Cincinnati Rock Songs)
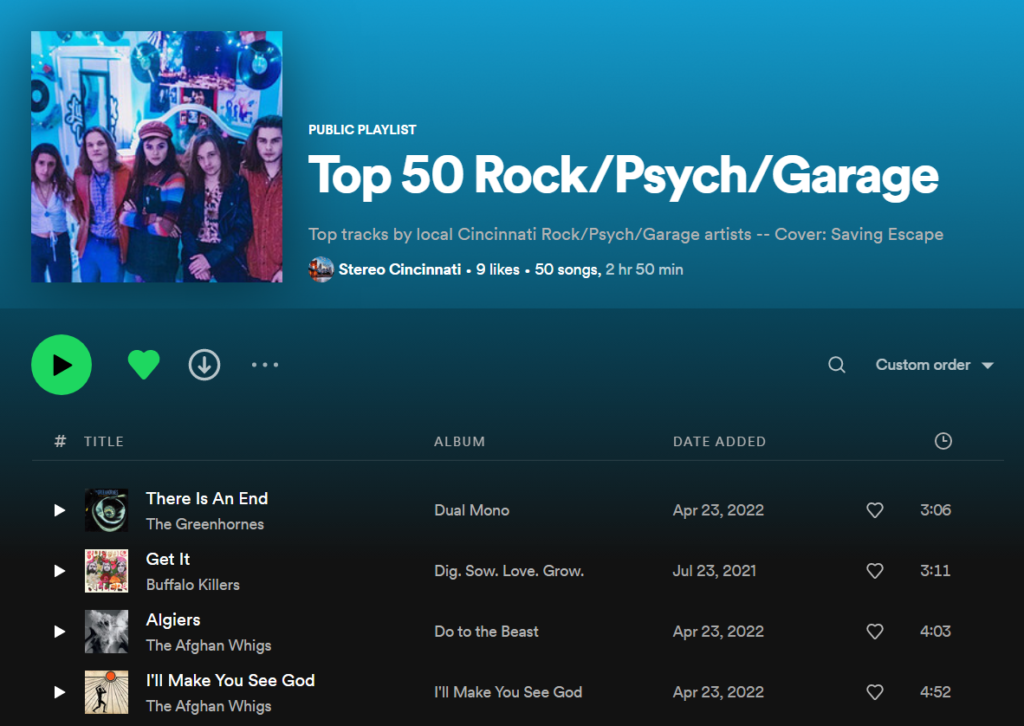
That’s it! Local music has become data-driven in just these steps above.

3. Possible Next Steps I Considered
- Spotify’s provided artist genre data I found to be very inaccurate for the local bands I was looking at, an it was hard to scrape public blogs and websites for genres.
- I would be curious to learn more about how Spotify’s genre assignment works and where it can go wrong. If I was able to figure out a way to classify an artist’s genre with greater accuracy than Spotify, this would allow me to potentially expand this analysis to other cities with more confidence and reliability.
- For a brief period of time, I was considering moving to San Francisco for work. During this period, I tried doing a similar project Stereo San Francisco. I was able to scrape and pull back a lot of artists, but I struggled heavily with the genre classifications. Not knowing if genres were correct and finding a lot of misclassified genre information from Spotify held me back from pursuing this any further.
- I also started to look into scraping any lyrics from local bands to do some analysis there. Maybe a bit unsurprisingly, not many of the local bands had lyrics posted to Genius, where I had initially tried to look via their API.
The Results
Once the project was completed, I was elated! Most importantly, I immediately discovered some amazing new local Cincinnati artists that I had never heard of before (some of those top of mind include Sungaze, Pomegranates, Vacation, and Greg Dulli.) I shared out the results via my new blog and Instagram and got a lot of great and positive feedback from family, friends, and beyond. I even had a couple of really great conversations with artists I truly admired over Instagram as I had tagged them in a couple of Instagram stories highlighting their accomplishments. It was an exciting time.
Over time, I had created the two blog posts mentioned earlier, but I started to run dry on new blog post ideas. I started to struggle a bit with the data-driven approach to local music, for as a discovery tool it served me very well, but now I was stuck on how to write relevant and topical data-driven posts about what else was happening in the music scene. Then, I got a bit reflective.

The Reflection
At one point, I started to feel a bit bad for layering over data to the fun and innocent local music scene (even though the playlists hadn’t really gotten that significant of attention). At the height of this feeling starting to creep into me, I added this section to the About portion of the blog:
The philosophy: Obviously, success in music is not all about popularity and Spotify streams. I have no wish to create an overly competitive local music environment that’s hyper-focused on streams – that’s no fun and defeats the purpose of art. This is just meant to be a fun project to help “organize” the local music scene to an extent so that it’s a less overwhelming community to explore. Newer listeners can enter the scene with the “Top Local Tracks”, then move onto finding their favorite local artists and supporting them. Ultimately, I hope it can create a more vibrant community that’s easier for local fans to keep track of be a part of.
I don’t think anyone else was really concerned at all about what I was doing, I think I was really the one the most concerned about the “danger” of my mildly popular but mostly unknown local playlisting project. I had excerpts from the book Weapons of Math Destruction (a great read about the dangers of algorithms) playing in my head and I certainly didn’t want to be the one to add even an ounce of toxicity to a warm, loving, and free-spirited music scene.

I do not believe that algorithms are always bad, but I do believe that they often have tradeoffs that can be easily overlooked. There are already a lot of great views from either side for algorithms in general (For instance, Pew Research: Pros and Cons of the Algorithm Age). But, I would like to tailor some of these arguments toward this specific local music project. So, you could argue the below Pros/Cons about the local music scene being driven by an algorithim:
PROS
- It eliminates biases – Spotify metrics ignore the identity of your band, and leave it simply up to the number of streams
- It eliminates nepotism – It is always easier to get a write-up in a local newspaper or blog if you happen to know someone working there. For artists who don’t have any connections, they must simply just wait and hope that someone will show up to their show.
- It helps newcomers by enabling easier discovery – I talk to many of my friends who are outside the local music scene and there is one resounding theme, they don’t know where to start. The local music scene is free-spirited, diverse, and runs on a lot of tribal fanbases that spread their genre’s best show opportunities by social and word of mouth. But for someone on the outside, it takes a lot of research to find local bands that are in their genre.
CONS
- It is subject to exploitation – If the local music scene did switch to a stream-based discovery system, then this system could easily be abused. Artists could let their tracks play over and over to boost streams, or even buy streams (if they can afford it). This would allow artists to artificially inflate their numbers, similar to Fake Reviews on Amazon.
- It reinforces already popular bands – Part of the fun of the local music scene is discovering bands at their earliest stages. Those who can recall seeing Walk the Moon in the early 2010s speak on those times as special memories. The problem with only looking at local bands who are already popular, is that the bulk of streams may start to migrate to those popular bands, rather than attention to newly/fresh bands who are craving an audience (even if its 5-10 people!).
- It could create a competitive environment – The local music scene is fun. It’s filled of goofy characters, fun nights, and fantastic individuals. Currently, there is no way to “rank” how your band is doing against “the others.” Because of this, it creates a very flat power structure. You can play with a band who has 1,000 local followers when you have 10 local followers and everyone treats each other the same way regardless. If there is more of a focus on rankings like Billboard 100, it could create some status and resentment between different popular and less popular artists. That may take away some of the magic.
Conclusion
I very much enjoyed this project from finding the artists, to creating the playlists, to writing a couple of blog posts. I look back on this project quite fondly but I’m ready to move onto a more general thought and publishing space, hence why I started the Off Road Analyst blog.
I encourage others to think about how they can help their local community via technology, while also considering the potential drawbacks of any solutions you may try. This project was a great learning experience, social experience, and philosophical experience for me and I hope to find a project just as engaging in the future.
Thank you for reading! If you have any feedback or thoughts, would love to continue the conversation — add a comment below! Or, you can reach me directly at @JacksonBurton11 on Twitter or email me at jacksonburton04@gmail.com.
If you’d like to stay up to date on any future Off Road Analyst posts, sign up below!